Beyond the symbolic vs non-symbolic AI debate
There has been recently a regain of interest about the old debate of symbolic vs non-symbolic AI. I argue here that the core questions for AI are of a different nature.

There has been recently a regain of interest about the old debate of symbolic vs non-symbolic AI. The latest article by Gary Marcus highlights some success on the symbolic side, also highlighting some shortcomings of current deep learning approaches and advocating for a hybrid approach. I am myself also a supporter of a hybrid approach, trying to combine the strength of deep learning with symbolic algorithmic methods, but I would not frame the debate on the symbol/non-symbol axis. As pointed by Marcus himself for some time already, most modern research on deep network architectures are in fact already dealing with some form of symbols, wrapped in the deep learning jargon of “embeddings” or “disentangled latent spaces”. Whenever one talks of some form of orthogonality in description spaces, this is in fact related to the notion of symbol, which you can oppose to entangled, irreducible descriptions.
There is actually something deeper than this surface difference about symbols that is at play here and it has to do with the learning experience itself. There are mainly two axis where I see a spectrum of variation, and which should help to think about the right way to go beyond the current dominant paradigm:
- The way new information is internally modifying the system, in other words: the learning mechanism itself.
- How new information is acquired and fed into the system.
Let’s examine how today’s neural network approaches position themselves relative to these two questions, and what alternative (and complementary) path can exist, which would lead to fruitful extensions of the current paradigm and potentially help solve the shortcomings that the critics of deep learning have been voicing.
Disclaimer: to be clear, because the debate is quite hot, I’m not saying here that deep learning is hitting a wall, or that it should not be pursued. My point here is to advocate for complementary and alternative approaches, that will reinforce deep learning and AI in general. Much progress is certainly going to come from recent research efforts in deep learning, and these results will play a central role solving strong AI, but I believe this is only a part of the solution. Let’s see why in the discussion below.
Differentiability is not all you need
What characterizes all current research into deep learning inspired methods, not only multilayered networks but all sorts of derived architectures (transformers, RNN, more recently GFlowNet, JEPA, etc), is not the rejection of symbols, at least not in their emergent form. It is rather the requirement for end-to-end differentiability of the architecture, so that some form of gradient-based method can be applied to learning. It is a very strong constraint applied to the type of solutions that are explored and is presented as the only option if you don’t want to do an exhaustive search of the solution space, which obviously would not scale (a critic often directed against classical AI symbolic methods).
The idea of gradient descent mixes two things: gradient, and descent. The “descent” part rightfully argues for a process of small step updates towards improvement of a local solution: indeed, if you don’t have an oracle that could reveal what you have to do, then directly “jumping” to a good solution starting from anywhere is not possible. There is simply no criteria to “calculate” the global jump. All you can do is try to move progressively towards a better solution, knowing where you stand at the moment.
Now, making a small step move is one thing, but how exactly to perform that move? This is the “gradient” part. If you have the luxury of being able to compute a gradient, then this is the optimal choice: simply move slightly along this gradient in the direction of improvement, recompute the gradient once arrived at destination, rinse and repeat until you reach a (local) minima. There are of course many refinements around this idea (SGD, ADAM, etc), but the core principle is the same: if you have a gradient, you have a “local oracle” that tells you where to go locally to improve your current bet.
I would argue that the crucial part here is not the “gradient”, but it is the “descent”, or the recognition that you need to move by small increments around your current position (also called “graduate descent”). If you do not have a gradient at your disposal, you can still probe for nearby solutions (at random or with some heuristic) and figure out where to go next in order to improve the current situation by taking the best among the probed locations. Having a gradient is simply more efficient (optimal, in fact), while picking a set of random directions to probe the local landscape and then pick the best bet is the least efficient. And all sort of intermediary positions along this axis can be imagined, if you can introduce some domain specific bias in the probing selection, instead of simply picking randomly.
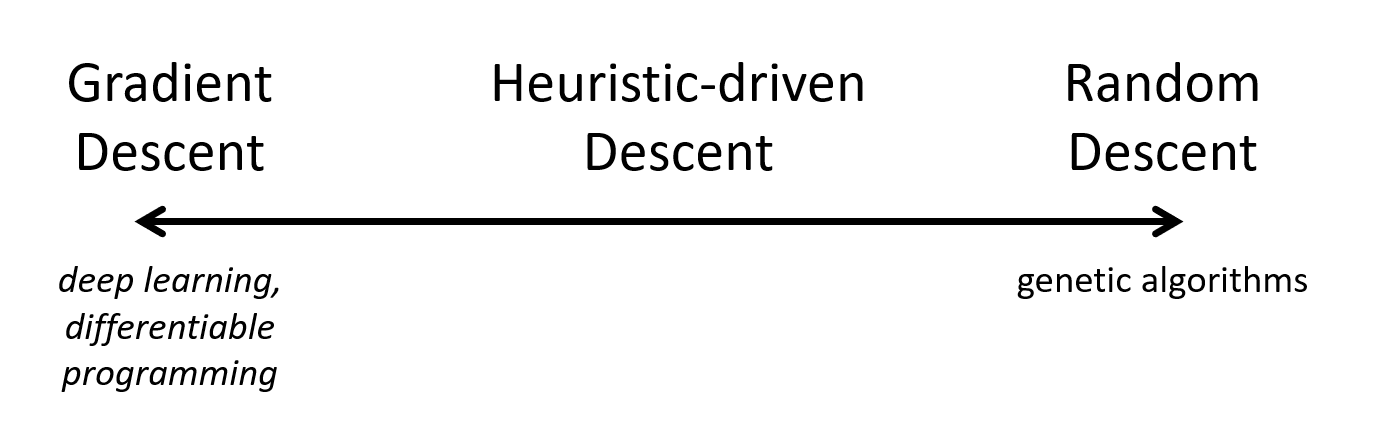
The typical example of a search using random probing around the current position is of course evolutionary dynamics. In the case of genes, small moves around a current genome are done when mutations occur, and this constitutes a blind exploration of the solution space around the current position, with a descent method but without a gradient. In general, several locations are explored in parallel to avoid local minima and speed up the search. Evolutionary dynamics in general is applicable to many domains, starting with the evolution of language, and is an extremely successful method to explore certain solution spaces for which no gradient could simply be computed (they are continuous, but non-differentiable spaces).
There are two notable caveats here: first, we still assume that the solution space is somehow continuous, which means that the quality of a solution does not vary abruptly in a small vicinity in the solution space, and it makes sense to probe for local variants. A counter example of this is, for example, hash functions which are designed precisely against this property. If you target a particular output for a hash function, then your only option is to randomly try until you find a match (what bitcoin hash challenges are based on). So there is really nothing to “learn” here and asking for continuity, or at least piecewise continuity, is probably a reasonable constraint to hold in the context of learning. Second, the dimensionality of the solution space could be so large that random search, even simply around a known solution point, is not tractable. This is, I believe, a typical case where we would need to put the cursor somewhere in the middle of the gradient-random axis, and introduce heuristics to guide the search. This is, to some extent, what is already done with AlphaGo or similar recent systems when a deep learning oracle is used to guide an otherwise more systematic search. Also, algorithms like CMA-ES effectively compute an approximated gradient from a purely random sampling strategy and would come right in the middle of the axis, as well as what are called “black box optimization” algorithms in general.
Another interesting subtopic here, beyond the question of “how to descent”, is where to start the descent. You can of course pick the initial condition at random, or start from several positions to avoid local minima, but this is actually a far more complex question involving research in curiosity-driven exploration, and more generally the exploration-exploitation debate, which is beyond the scope of this discussion.
So, getting back to the topic, the core limiting issue with deep learning, or more generally “differentiable programming”, is not its rejection of symbols (symbols are somehow handled in an emergent way), but its focus on handling only solution spaces that happen to allow for a gradient computation. There is of course nothing wrong with studying these cases, and whatever the solution to strong AI is, one can bet that gradient-based methods are going to be a crucial part of it, but contrary to what is often claimed there is simply no scientific reason to think this should be the only way forward, with a strong rejection of anything not “fully differentiable”. The differentiable/non-differentiable axis exists and I suspect that many core problems of strong AI, like language grounding or even self driving cars, require solutions that are located somewhere along this line. Combining differentiable methods when applicable together with evolutionary dynamics on discrete (=symbolic) structures when appropriate has the potential to yield substantial progress in the field.
I cannot resist to make a small digression here, about a parallel that can be made with recent trends in physics. Until now, all successful physics has been formulated in the framework of differential equations, acting on continuous and differentiable variables. It is what Wigner called the “unreasonable effectiveness of mathematics in the natural sciences”. Recently, more and more researchers are exploring the possibility that Nature is best described at small scale by discrete structures, with evolution formulated as discrete transformation on these structures (see for example the work on Causal Sets, Loop Quantum Gravity, or even the Wolfram Physics project). It is as if, at some point, the unreasonable effectiveness is ending and reality cannot be approximated by models that offer gradients anymore: we have to get down to the raw “machine code” that is inherently discrete, step-wise, compositional and irreducible. One might wonder if these physicists are right (it’s difficult to come up with experiment proposals at that scale, so we might never know), and if some similar dichotomy is not also at play in AI, as discussed above.
Differentiable functions vs programs
Learning differentiable functions can be done by learning parameters on all sorts of parameterized differentiable functions. Deep learning framed a particularly fruitful parameterized differentiable function class as deep neural networks, capable to approximate incredibly complex functions over inputs with extremely large dimensionality. Now, if we give up the constraint that the function we try to learn is differentiable, what kind of representation space can we use to describe these functions? Well, the simplest answer to this is to move one step up in terms of generality and consider programs. They can be as simple as binary decision trees, or as complex as some elaborated python-like code or some other DSL (Domain Specific Language) adapted for AI.
Importantly, programs have the following properties:
- they are discrete in structure and therefore can easily be subject to mutations, powering a local non-gradient based exploration of solutions
- they are compositional, allowing not only mutations but crossover
- they are hierarchical in nature, allowing the building blocks from which programs are made to be programs themselves, enriching the expressive power of the search when trying to find new programs
Navigating the space of programs at random would not be efficient. Here is a case for hybridization: using deep learning methods, for example graph neural networks, to help guessing a starting point, and also to provide an oracle when probing around a given existing solution while performing the descent (instead of mutating the programs at random). We end up here somewhere in the middle of the gradient-random axis that we talked about above, with a not completely random but also not completely deterministic probing for a step in the descent. Note that a lot of very promising research on graph neural network already provide results on the oracle part mentioned above.
Another example of what can be done in terms of hybridization is how we could use a genetic algorithm to evolve a formal grammar for a particular language, using a large language model like GPT-3 as an oracle to compute a fitness by comparing the kind of sentences that the current grammar candidates are producing and assessing how statistically realistic they sound. This is a nice coupling of statistical evaluation (with all its approximations, but for a fitness it is acceptable) and formal structure evolution, which comes with many computational advantages once the final grammar has been stabilized.
As a side note, it’s interesting to see that the requirement of differentiable functions to process input data brings along the requirement to “flatten” data into vectors for input (or matrices, tensors, etc). This process loses the potentially recursive structure of the elements of the input space, which could be easily exploited by a program in a non-differentiable framework (think of graphs, hypergraphs, or even programs themselves as inputs). Of course, it is possible to recover some part of the structure in a neural network framework, in particular using transformers and attention, but it appears as a very convoluted way to do something that is a given in the natural initial form of the input data. Considerable efforts in terms of research time and computational time are devoted to work around the constraint of vectorization of compositional/recursive complex information, in order to recover what was already there to start with.
Human intelligence emergence is culturally driven
Now, let’s get to the second main point I wanted to discuss. Learning typically involves feeding the system with new information. It turns out that the particular way information is presented plays a central role here. Not just in terms of how fast it can converge, but, for all practical purposes (assuming finite time), in terms of being able to converge at all.
In most machine learning instances, information is fed to the system in batches. This is true in supervised learning, but also in unsupervised learning, where large datasets of images or videos are assembled to train the system. This leads to the establishment of benchmarks against which competing models are compared. The community is well aware of the fact that the order of presentation of learning examples is important (this is called “curriculum learning”), and that a careful selection of a good strategy to order the examples can lead to much better convergence speed, final performance or generalization.
What is much less often acknowledged is the importance of interactive learning, where the system not only absorbs data that is fed to it, but also actively participate in the building of learning situations from which new data can be acquired. This is called “active learning”. It allows to explores questions related to causality (where, ultimately, an active “acting” part is needed in order to go beyond correlation extraction), intrinsic motivation, and embodiment since the active part requires some form of actionable “motor” dimension in the system. These points are not really ignored by the deep learning community, at least not by people at the forefront of research, but the dataset approach remains dominant (in part also because it allows for well defined measures of progress and comparison of results). More generally, the prevailing philosophy is that more data leads to better learning, and that raw data is essentially all you need. It relates to the naive inductivist view that knowledge is somehow contained in data, and that we can squeeze it out by appropriate automated/deterministic means. This is not the case: for example, general relativity was not contained in direct observational data at the time of Einstein, as nobody had ever looked at the bending of light via gravity. It had to be invented, by a creative process, and then led to the acquisition of more data to confirm it. Most interesting theories cannot be created by “rephrasing” the data by statistical means, but must involve a creative process that contains some form of biased random exploration.
But the interactive nature of learning is not the only issue (and again, some researchers in machine learning are acknowledging this and working on it). I would argue that an isolated system, equipped with active learning and a body in a rich environment, would still not be able to reach significant levels of what we could recognize as human-level intelligence. Or perhaps, it would be able to reach a certain level of animal-level intelligence (which would arguably be a great achievement, but we are here for the strong AI game). It is often argued by the deep learning community that animal-level intelligence is a crucial step towards human-level intelligence, because the genome of animals being in fact quite similar to the one of humans (98% of common genes with apes, and more than 90% with most other mammals), so there cannot be a big step forward to human-level intelligence once you have animal-level intelligence. Therefore, we should focus on animal-level intelligence, and the rest would follow quickly. I believe this point of view is wrong. It is a genome-centric view that basically says that the developmental and cognitive trajectory of the organism is mostly explained by the genome. What is ignored in this reasoning is the monumental influence of another evolutionary body: human culture. The correct picture most likely involves a complex and entangled co-evolution of genes and culture in the case of homo-sapiens, and the 2% genome difference with apes might not code for an extra intelligence capacity, but simply for the extra bit of complexity that unlocks cultural dynamics, the “cultural hook” (more neurons to handle things like theory of mind, building joint plans with congenerates, etc), with otherwise a very similar general intelligence capacity. In fact, you might imagine building an AI with a very limited animal-level intelligence, but once you get the “cultural hook” it would be boosted to something close to human-level very quickly. In other words: to get to human-level intelligence, you need an agent that is actively learning while being immersed in a physical and cultural environment which is strongly influencing the developmental trajectory.

The different “ways” of learning that we talked about are not only related to curriculum learning (the order of presentation of examples), but to a vast repertoire of “learning games” that are ritualized learning interactions and strategies practiced by adults with infants, and then children and young adults, from kid’s play up to the more advanced ritualization that is modern schooling systems. In short: animal-level intelligence + cultural hook + cultural environment = human-level intelligence. And the animal-level part might not be the most crucial part in this equation. The cultural environment is important and complement the genomic environment, as it defines good strategies on “how” to learn, vs the current machine learning paradigm that takes an oversimplified view based on the non-interactive, non-social strategy of showing training examples from a dataset (which humans actually never do).
To summarize, a proper learning strategy that has a chance to catch up with the complexity of all that is to be learned for human-level intelligence probably needs to build on culturally grounded and socially experienced learning games, or strategies. This fits particularly well with what is called the developmental approach in AI (also in robotics), taking inspiration from developmental psychology in order to understand how children are learning, and in particular how language is grounded in the first years.
Key elements of the developmental AI program include, in order of complexity:
- embodiment and grounding symbolic abstractions into sensorimotor invariants
- interaction with a physical world (naive physics) but also with a social world (theory of mind)
- language evolution as a scaffold for socially grounded intelligence building
- human-specific social constructs like joint plans, joint attention, narratives (see for example Tomasello “Becoming Human” for a detailed analysis of human-specific social capacities)
Language in particular is approached here in a very different way compared to the today’s dominant NLP paradigm: instead of treating words and grammatical structures as superficially statistically related token, it sees words and grammar as the result of an evolutionary process trying to maximize a communication fitness, aiming at the execution of socially and environmentally grounded joint tasks, requiring cooperation and agreement on grounded meanings. The grounding is such that words refer to perceptual and conceptual categories that have proved useful to efficiently communicate, reach goals together and reduce ambiguity (words or grammatical structures that fail to meet these needs are “selected away” from the emergent language, via an evolutionary dynamics). This creates a grounded basis for language, immediately connected to physical and social reality, to goals and situations, to particular ways of categorizing the world such that the resulting categories are leading to successful interactions. Capturing this complexity in a machine would allow it to build grounded meaning (as a link between internal sensorimotor or conceptual categories and external word/grammatical token) and help resolve common sense reasoning traps in which the current NLP statistical machines fall and will continue to fall as long as no proper semantics is integrated in the learning process.
The semantic layer is not contained in the data, but in the process of acquiring this data, so the particular learning approach of current deep learning methods, focusing on benchmarks and batch processing, cannot capture this important dimension. The process of acquiring data, that we could call “learning games” is itself subject to evolutionary pressure and constitutes an asset that an intelligent human benefit from immediately after being born, when the first interactions with the parents start, and then further on when subject to learning via the ritualized methods invented by his/her community. This crucial aspect of learning has to be integrated into the design of intelligent machines if we hope to reach human-level intelligence, or strong AI.
VR as an efficient way to conduct experiments
At a more concrete level, realizing the above program for developmental AI involves building child-like machines that are immersed in a rich cultural environment, involving humans, where they will be able to participate in learning games. These games are not innate (they are part of the cultural background, so they are subject to another type of evolutionary dynamics than the one of the genes), but must be learned from adults and passed on to other generations. There is an essential dissymmetry here between the “old” agents that carry the information on how to learn, and the “new” agents that are going to acquire it, and possibly mutate it.
Learning games involving only the physical world can easily be run in simulation, with accelerated time, and this is already done to some extent by the AI community nowadays. For the social dimension, involving interactions with humans, virtual reality headset are a very promising interface allowing natural interactions that include face expression (some VR headset support this already), gaze following, gesture and body posture, and many other non-verbal communication signals that are crucial to bootstrap the learning of language.

Without the help of VR, the only option that was on the table was to actually build robots that can interact with humans. This was the developmental robotics program, which I was involved with when I was at Sony, and later on at Softbank Robotics Europe. The thing with robotics is that you can’t avoid facing all the problems of embodiment and sensorimotor grounding face on. This is interesting, but it is also a very severe limitation: it makes it impossible to study higher level cognitive questions like language evolution, social interactions or causality induction, without first solving low level issues like grasping, motor control, walking, etc. If you add these issues to the fact that robots are expensive, require maintenance and lots of engineering efforts, you can see that the barrier to entry is high.
One very interesting aspect of the VR approach is that it allows us to shortcut these issues if needed (and only if we have good reasons to believe that the building up of the low level is not somehow crucial to scaffold the high level). One can provide a “grasping function” that will simply perform inverse kinematics with a magic grasp and focus on the social/theory of mind aspects of a particular learning game. We could go as far as providing a scene graph of existing and visible objects, assuming that identifying and locating objects could potentially be done via deep networks further down the architecture (with potential top-down influence added to the mix). The point is here to focus on the study of the cultural interaction and how the cultural hook works, not on the animal-level intelligence which is, in this developmental approach, not necessarily the most important part to get to human-level intelligence.
Conclusion
I’ve argued here for two main departures from the mainstream current paradigm in AI and machine learning:
- extend the scope of search methods from gradient descent to graduate descent, allowing the exploration of non-differentiable solution spaces, in particular solutions expressed as programs.
- the learning strategy should go beyond batch learning and towards interactive, embodied social learning, framed as “learning games” that are themselves subject to evolution. The necessary real-time interaction with humans suggests that VR would be a good tool to setup experiments and learning environments.
I believe that these are absolutely crucial to make progress toward human-level AI, or “strong AI”. The current quasi-exclusive focus of academia and the industry on end-to-end differentiable models is detrimental to the field, and incredible progress is probably just around the corner if we simply consider the complementary idea of non-differentiable models and take it seriously, without framing the question on symbolic vs non-symbolic AI, which I believe is not the core issue here. It’s not about “if” you can do something with neural networks (you probably can, eventually), but “how” you can best do it with the best approach at hand, and accelerate our progress towards the goal.
References
Michael Tomasello. The cultural origins of human cognition. Harvard University Press, 1999.
Luc Steels and Jean-Christophe Baillie. Shared grounding of event descriptions by autonomous robots. Robotics and autonomous systems, 43(2–3):163–173, 2003.
Josh Abramson, Arun Ahuja, Iain Barr, Arthur Brussee, Federico Carnevale, Mary Cassin, Rachita Chhaparia, Stephen Clark, Bogdan Damoc, Andrew Dudzik, et al. Imitating interactive intelligence. arXiv preprint arXiv:2012.05672, 2020.
Anirudh Goyal and Yoshua Bengio. Inductive biases for deep learning of higher-level cognition. arXiv preprint arXiv:2011.15091, 2020.
Judea Pearl. Causal and counterfactual inference. The Handbook of Rationality, pages 1–41, 2018.
Alan M Turing. Computing machinery and intelligence. Mind, 59(236):433–460, 1950.
Jean-Christophe Baillie. Artificial intelligence: The point of view of developmental robotics. In Fundamental Issues of Artificial Intelligence, pages 415–424. Springer, 2016.
Brenden M Lake, Ruslan Salakhutdinov, and Joshua B Tenenbaum. Human-level concept learning through probabilistic program induction. Science, 350(6266):1332–1338, 2015.
Luc Steels and Manfred Hild. Language grounding in robots. Springer, 2012.
Laland, K. N., Uller,T., Feldman, M.W., Sterelny, K., Müller, G. B., Moczek,A. et al. The extended evolutionary synthesis: Its structure, assumptions and predictions. Proceedings of the Royal Society B, 282(1813), 1–14, 2015.
Marta Garnelo, Kai Arulkumaran, and Murray Shanahan. Towards deep symbolic reinforcement learning. arXiv preprint arXiv:1609.05518, 2016.
Pierre-Yves Oudeyer and Frederic Kaplan. What is intrinsic motivation? a typology of computational approaches. Frontiers in Neurorobotics, 1, 2007.
Linda Smith and Michael Gasser. The development of embodied cognition: Six lessons from babies. Artificial Life , 11(1–2):13–29, 2005.
Thanks to Alban Laflaquiere and Pierre Yves Oudeyer.