Why AI Needs a Body
Deep Learning, while a fantastic technology, is not the whole story for AI. Embodiment is also a crucial aspect, an opinion that is nowadays shared by many researchers in fundamental AI.

I’ve already mentioned in a previous article why I thought Deep Learning, while a fantastic technology, was not the whole story for AI. At least if we are talking about Artificial General Intelligence which aims at capturing the versatility and incredible flexibility of human intelligence. In particular, I stressed the fact that embodiment was a crucial aspect, an opinion that is nowadays shared by many researchers in fundamental AI.
In this article, I would like to go a bit deeper on this notion: why would a general AI need a body and interactions with the real world? Why couldn’t we just get it to digest huge amounts of data and make sense of it? What does the embodiment actually bring to the table, and can we find an example of something that could not be achieved by a disembodied AI? All these questions are crucial to better understand the limitations of today’s AI systems.
The first thing to realize is that by passively observing phenomenons and collecting data on them, one can only extract correlations, not causation. To establish causation, you need to physically act on the system you study, and observe the consequences. I recommend the reading of the very good book by Judea Pearl, “Causality”, talking extensively about this distinction. A famous illustration is given by Pearl when he highlights that there is no way to prove that smoking causes cancer on the basis of the correlation data alone. There could be a hidden gene that causes both a craving for smoking and a predisposition for lung cancer. The only way to establish this causation (ignoring other scientific facts about the way cancer develops and why it’s most likely caused by the accumulation of tar in the lungs) would be rather unethical: you would have to take a large unbiased sample of the population, split it into two groups, one that is forced to smoke, and one that is prevented to smoke. You would then measure the rate of cancer in both groups. If they are equal, then smoking does not cause cancer, otherwise it does. The act of making those two groups is a physical action in the world, and this is the only recipe to actually establish causality in a strong sense.
So, you need to act in the world to extract causation from data and not only correlations. But what’s wrong with correlations? After all, they are depicting real trends that are informative. Well, not really. When people say “informative”, they mean “causally informative”, or “predictive”, and we just saw that this was not accessible through correlations only. Another good example of this limitation is the Simpson’s Paradox. This paradox highlights situations where you can have a very strong correlation by looking at agglomerated data, but paradoxically anti-correlations when looking at sub-part of the data. Example: admissions to University of California in 1973 would show a clear trend: 44% of men applying were admitted, while only 35% of women did. Would you deduce that there is a causal link between being a men and being admitted? Wrong. Looking at the results per department, so looking at a sub-sample of the data, it appears that the rate of admission is greater for women in 4 departments out of 6, and the remaining 2 departments are won by men with a very small margin. The truth is, women tend to apply for departments that are harder to get admitted into, hence the global shift in correlations.
As a consequence, if you are looking for causal relationships, you will need to act in the world (Pearl introduced the “do” operator to extend traditional probability theory and take into account this aspect), and to act in the world you will need a body. This is the price to pay to be able to go beyond correlations, which are not telling you anything about the causal structure in the world. This in itself is already a good reason why embodiment would matter for AI. But there is more. The outside world is not random and it contains structures, regularities. It follows the laws of physics, as far as we can tell. An embodied AI could make use of this to create new facts and extend its axiomatic about the world, as I will show in an example below.
I should mention here a central problem in AI, related to the question of “where would the concepts learned by the AI come from”, also called the “problem of grounding”, which I briefly expose in my previous article about AlphaGo. The sensorimotor theory, championed by Kevin O’Regan, argues that the answer to this fundamental question comes from the tight interplay between action and perception. Abstract concepts are the invariants of the particular way in which my actions and my perceptions are coupled. It starts with my body, which, because of its shape, exhibits a set of invariants about how my movements can affect the world and my perception of it around me. And then it grows progressively towards more and more abstract concepts, built on top of these primitive sensorimotor grounded concepts.
Following this trend, everything I conceptualize is, to some extent, connected down a hierarchy of less and less abstract concepts, down to the core concepts that are grounded by interactions with the world. Even very bizarre mathematical concepts are grasped by competent mathematicians in an “intuitive” way. Making analogies, building on familiar visual representations, the tools of the mathematician can be ultimately very abstract but down the hierarchy of concepts, it is grounded. Take fractional dimensions for example: we can all grasp what is a 2D structure or a 3D structure, but what exactly would a 2.3D structure be? Introduce fractals, visualize such a structure and you start to get an intuitive perception of these not-quite-flat but not-quite-filled volumes that actually represent a 2.3D structure.
Let’s take now an example to illustrate the power of concept generation that comes from being immersed in a physical world that has some internal structure, with a physical body. On one side, let’s have a formal AI system, capable of manipulating symbols in a logical way, using analogies, inferences, etc. On the other side, we will have the same AI system, but with two main differences: all the symbols that it will manipulate are grounded in the physical world, and it can also act in this world. Now, let’s feed these systems with the following facts:
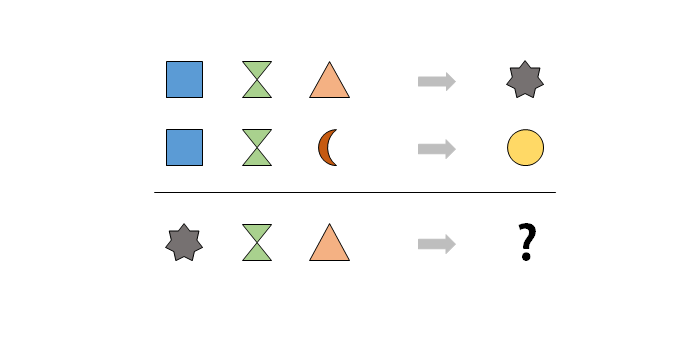
The first two lines are transformation rules known to the system, and the third line is the question to answer. The pure formal system has no chance of finding the solution. Each of the symbol carries no meaning to it, it is in no way connected to a physical grounded notion and no matter how hard you try to rewrite the rules, factor them or use analogy, you can’t get to the answer.
Now, the second system has grounding. It is equipped with a perception system capable of triggering different signals depending on the number of similar entities present in its visual field (something that most animals and humans are capable to do, at least up to the number three). It has grounded the symbol “square” with the visual notion of “oneness”. Whenever it sees “one stone” on the table, the system will internally trigger this “square” signal. Similarly, it mapped the “property of being two” to the symbol “triangle”, three to the “gray star”, four to the “crescent” and five to the “gold circle” (these symbols are chosen by me purposely to have no intuitive meaning, they could be anything, including complicated internal states of a neural network). The system has also grounded the physical action of gathering objects in front of him, which is a complex sensorimotor invariant, with the symbol “two inverted green triangle”. That being said, quite obviously for us the above enigma is nothing more than: “1+2=3, 1+4=5, 3+2=?”. The answer is 5, the “gold circle”.
Unlike the pure formal system, the physically embodied system has another source of knowledge acquisition at its disposal. It can try to perform the physical gathering of “three-ness” and “two-ness” with its hands acting on some stones on a table, as suggested in the question asked by the “two inverted green triangle” symbol, and use its number perception system to observe the result. The perception system will recognize “five-ness” and trigger “gold circle”, giving access to a new fact to our lucky system. This fact is not random, it’s the expression of the spatio-temporal continuity of the physical world, and it is in fact its true meaning. The world could be otherwise (and indeed it is at small scale, as quantum mechanics has demonstrated), but for all practical purposes at our scale it is not, as countless experiments have shown. The kind of relationships that exist between the grounded symbols that our embodied system can learn is constrained. It will ultimately be able to observe regularities in the action of “adding one stone to a group of n stones”, therefore getting to sketch the basis of the Peano arithmetic, and later on the whole Number Theory. This all comes from the interplay between perception, action, and a system embodied in a physical world with some regularities. Statistical passive observation of already known facts is not sufficient for the first system to come to any conclusion.
This toy example captures something fundamental about knowledge acquisition but also the nature of knowledge accessible to AI systems. Beyond this trivial example lies more complex and subtle situations where a traditional “statistical AI”, based on pure observation and no grounding, will find its limits. Our way of talking and reasoning, as humans, are filled with analogies to space and physically grounded notions. We think with our bodies. It means that the future of AI depends on grounded AI, which is robotics, and the capability we will give to the system to interact with the world. This knowledge cannot be defined in an abstract way, but must be built by the system itself as it learns the peculiarities of its own embodiment. With similar enough embodiment, you can hope to ground concepts that language and cultural learning will be able to synchronize between the different participants.
This, in a nutshell is the program of Developmental Robotics, which is taking the young child as a model to try to build incrementally learning AI system. In my opinion, this is perhaps the most promising direction of research for Artificial General Intelligence. It is following in the footsteps of Alan Turing when he wrote, in his 1950 paper “Computing Machinery and Intelligence”:
Instead of trying to produce a programme to simulate the adult mind, why not rather try to produce one which simulates the child’s?
This visionary program has still yet to be implemented.